
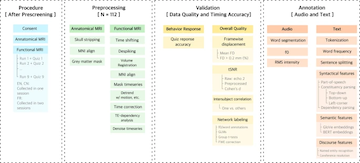
Jixing Li let a large team to prepare these unique neurolinguistic datasets. Speakers of English (49), Mandarin (35) or French (28) listened to a 1.5 h audiobook of The Little Prince during fMRI scanning. The full MRI datasets are released along-side numerous linguistic annotations including prosodic contours, GloVe embeddings, POS tags, constituency parses, dependency parses, and more! We can’t wait to see what the scientific community can do with these data.
Take me straight to the data! OpenNeuro ds003643
Li, J., Bhattasali, S., Zhang, S. et al. Le Petit Prince multilingual naturalistic fMRI corpus. Sci Data 9, 530 (2022). https://doi.org/10.1038/s41597-022-01625-7
Abstract
Neuroimaging using more ecologically valid stimuli such as audiobooks has advanced our understanding of natural language comprehension in the brain. However, prior naturalistic stimuli have typically been restricted to a single language, which limited generalizability beyond small typological domains. Here we present the Le Petit Prince fMRI Corpus (LPPC–fMRI), a multilingual resource for research in the cognitive neuroscience of speech and language during naturalistic listening (OpenNeuro: ds003643). 49 English speakers, 35 Chinese speakers and 28 French speakers listened to the same audiobook The Little Prince in their native language while multi-echo functional magnetic resonance imaging was acquired. We also provide time-aligned speech annotation and word-by-word predictors obtained using natural language processing tools. The resulting timeseries data are shown to be of high quality with good temporal signal-to-noise ratio and high inter-subject correlation. Data-driven functional analyses provide further evidence of data quality. This annotated, multilingual fMRI dataset facilitates future re-analysis that addresses cross-linguistic commonalities and differences in the neural substrate of language processing on multiple perceptual and linguistic levels.