We’re very pleased to have received an NSF CRCNS grant to develop computational models of brain systems involved in sentence comprehension. This is part of a collaboration that includes John Hale (Cornell), funded under a separate award, and Christophe Pallier and colleagues (Paris) funded under an award from the ANR.
The basic idea of the project is this: Computational neuroscience has matured to the point where ideas from computational linguistics may now be applied to the analysis of neural signals. This offers a new way of studying human language in the brain. While dominant models assign intuitive verbal labels to nodes of the “language network” (for example, see the articles collected in the mega-volume edited by Hickok and Small), new investigations of information flowing through this network use explicit language models based on n-grams, dependency relations and even phrase structure (e.g. Wehbe et al., 2014; Willems et al., 2015, Brennan et al., 2016). Applying increasingly realistic conceptualizations of sentence structure, this new approach goes beyond intuitive verbal labels by matching particular mechanisms to particular nodes of the brain’s language network. Our project for the first time rigorously compares alternative candidate mechanisms of language comprehension.

Read on for more details!
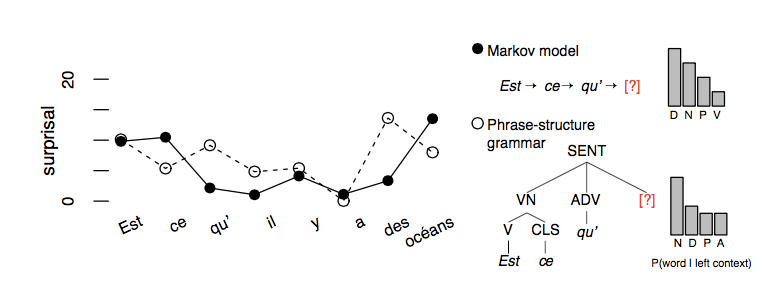
We develop models that integrate parsing algorithms with information-theoretical complexity metrics which have been widely applied at the behavioral level in psycholinguistics. These neuro-computational models yield time-locked predictions about stimulus texts; for instance that a word should be particularly difficult because it is unexpected in context. We apply the models to naturalistic narratives such as The Little Prince and its translation from French into English. We test model-derived theoretical predictions against data that is collected using electroencephalography (EEG) and functional neuroimaging (fMRI), across both languages. The fit or lack thereof between the predictions and the neural signals drives the development of more realistic models. The innovative idea is that the same notion of parsing algorithm, as studied in computer science, may also serve as a theoretical model of brain function.
With these models, we pursue two specific questions regarding language comprehension in the brain:
- What aspects of sentence structure determine our expectations for upcoming words?
- What is the detailed balance between memorization and composition in natural language?
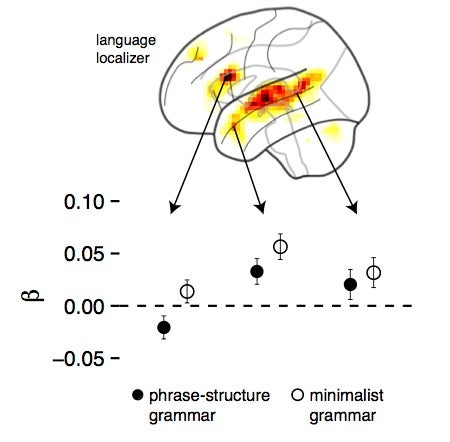
For the first question, we computing alternative predictions from neuro-computational models that differ in the “domain of locality”, or size of the recombinable units of analysis. Doing so allows us to test which theories of sentence structure align best with neural signals collected under “everyday listening” conditions.
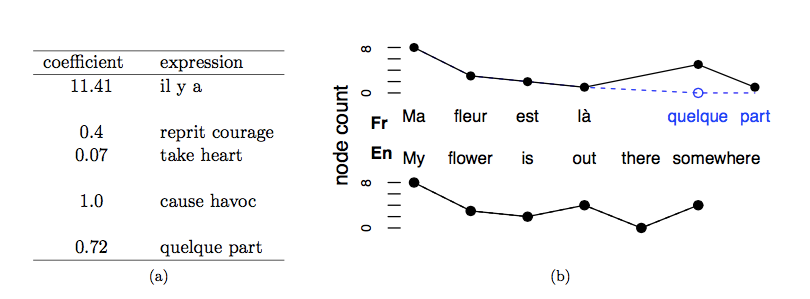
The team’s experience with “multi-word expressions” facilitates the investigation of question (2). These are strings of words that are likely to be retrieved from memory as opposed to being composed on the fly. They operationalize a central distinction between two types of comprehension that engage different neural circuits.
The Team
| John T. Hale | Linguistics and Cognitive Science | Cornell University |
| Wen-Ming Luh | Cornell MRI Facility | Cornell University |
| Jonathan Brennan | Linguistics and Psychology | University of Michigan |
| Christophe Pallier | Cognitive Neuroimaging | Université Paris Saclay |
| Asaf Bachrach | Structures Formelles du Langage | Université Paris 8 |
| Éric de la Clegerie | INRIA | Université Paris Diderot |
| Mattheiu Constant | INRIA | Université Paris Diderot |
| Benoît Crabbé | INRIA | Université Paris Diderot |
| Benoît Sagot | INRIA | Université Paris Diderot |