
Michigan math PhD student Ethan Zell wrote to share his experiences with an internship last summer, where he contributed to a project using AI to diagnose heart conditions at the data science start-up Mined XAI. Ethan is working with Professor Asaf Cohen and on track to defend his thesis on finite state mean field games in Spring 2024.
Ethan hopes other Michigan math PhDs will find it helpful to hear about his experiences pursuing non-academic career options, including what and how he’s learned from our alumni such as Mark Greenfield or others who have blogged on this site, as well as some of the specific projects he’s worked on.
In Ethan’s words…
Maybe your interest in a life outside the academy started like mine. I love doing math research—really, I do. Learning from and working with my research advisor has taught me to approach problems carefully and with different strategies—most of these strategies fail, but in math only one has to work.
Sure research is excellent, but for me enjoying the work is not enough to justify the life academia offers—moving cities often, job uncertainty, and mediocre pay are tough pills to swallow. I felt that I had passion for research, but I’m passionate about many things and I asked myself, why couldn’t I be passionate about a new career? Hopefully, this alternative would scratch the same “mathematical thinking” itch, but without the downsides of academia.
First Steps
About two years ago, I began to consider quantitative roles in industry. I spoke with my advisor, with professors like Karen Smith, and with my family. I began attending the Erdös Institute’s Invitations to Industry seminar series. I reached out to alumni and asked for their stories. Here are a few of the diverse paths I learned that UM math PhDs have taken: entrepreneur (doing data consulting), consultant, quantitative researcher, cryptocurrency trader, principal research scientist, business strategist, and data scientist.
Most of these roles have a few things in common. First, they require some knowledge of programming. Second, the roles usually wanted some deeper understanding of statistical or machine learning techniques.
I had taken programming courses in Python and Java as an undergrad so I at least felt comfortable with a Jupyter notebook open. Then as part of my M.S. in applied math at Michigan, I took two courses in the electrical engineering and computer science department [EECS 592 (Foundations of Artificial Intelligence) and EECS 505 (Computational Data Science and Machine Learning)]. While I had a good understanding of probability theory, the abstract probability theory I knew differs a lot from the techniques used in industry; this would be something to work on.
The Erdös Institute
I decided that going for a data science internship would be a good way to broadly prepare myself for many different roles. Unfortunately, while my studying focused on understanding data science tools and techniques, I underestimated the importance of quickly recalling the main data science Python libraries–at the time, pandas and sklearn were pretty new to me.
My inexperience made applying for internships during the fall semester challenging. Often my resume would get me to a screening round of some kind, but I struggled to solve timed programming problems. While I was confident that I could solve the challenges with enough time, my inexperience with key data science libraries slowed me down.
To bridge this gap, I enrolled in the Erdös Institute’s data science boot camp. As the founder of the Erdös Institute puts it, they “help PhDs get the jobs they love.” The boot camp prepares PhDs for data science roles and features examples for students to practice using the Python libraries I mentioned. The boot camp adopts a “this is really for your benefit so whether or not you do the work is up to you” mentality; so suffice to say it was low stress. Still, I took the examples seriously and tried to do all the work before the answers were released. Sometimes this meant I learned a different way of doing the same task.
Toward the end of the boot camp, participants form teams to produce a “capstone project”–that is, a deliverable that solves a real world problem using techniques learned in the boot camp. For the project, I teamed up with a small group of peers–other Michigan math PhDs. We had varying programming backgrounds but had a common language–math–and found it easy to cooperate.
Movie Finder–A Capstone Project
For our capstone project we built the app “Movie Finder.” Movie Finder allows a user to enter some details they remember about a movie and then predicts what movie the user is thinking of. Of course, the main challenge is that a user’s input–which is already highly variable–needs to be mapped to the correct movie, even when the input is partial. A natural solution then, is to try to semantically match the user’s input to a movie plot summary. Once a match is found, just have the program return the name of the movie corresponding to the plot.
As we discovered early in the project, movie plots from certain sources (Wikipedia, for instance) were lengthy and had many references to actors, themes, and other items that were not plot related. Some plot descriptions also used overly-formal word choice and would not map well to a user’s input. Luckily, IMDB has a specific page of user-generated plot summaries. This was perfect for Movie Finder. The IMDB user summaries were shorter, more informal, and captured moments that stuck in a viewer’s mind. Most importantly, each summary was generated by a single (amateur) user, rather than a professional movie reviewer or a cohort of people, as in the case of Wikipedia.
My main contribution to our team was writing Python scripts to scrape the IMDB user summaries in order to build the dataset. The boot camp had taught the basics of web scraping, including a brief survey of the BeautifulSoup Python library, which came in handy. Once the data was scraped, I used the Natural Language Toolkit (sometimes just called NLTK) library to write functions to clean up the plot descriptions’ punctuation, and to split the plot descriptions into parts based on the number of sentences. The idea to split the descriptions into parts came from the assumption that longer descriptions contained information from different acts in the movie. Since we were ultimately matching sentences with similar contexts, a description with too much context could cause confusion (eventually testing confirmed just that).
We had only a week to finish Movie Finder. So our team worked quickly to fix genre categorization issues, build the cross-encoder for description matching, and test the various decisions we made along the way. When our end product scored a laudable 84% accuracy on a testing set, we finally called it a week. A few days later when our project received the first prize out of forty-seven teams participating in the capstone challenge, we were proud and surprised.
Mined XA
During the Erdös Institute boot camp, I spoke to Roman Holowinsky, a professor at Ohio State and the Institute’s founder and managing director. He was nice enough to chat with me one on one and even took a look at my resume. During our conversation, Roman mentioned several Erdös Institute partners who were looking for a PhD interested in data science, one of which was Mined XAI. Following his advice, I applied to their posting and began a back and forth with Kyle Siegrist, the CTO of Mined XAI (and spoiler, my future boss).
In a Zoom interview with Kyle, he asked about the Erdös Institute, my background in programming, my research, and my goals. We talked about Mined XAI and topological data analysis (their company’s speciality) and what I knew about it (nothing). Toward the end of the call, I got the sense that Kyle was happy with my answers and soon after I received an email from Mined XAI confirming an offer. I happily accepted!
The first few days at Mined XAI focused on meeting the team, understanding the company philosophy (explainability first), and familiarizing myself with Mined XAI’s proprietary algorithms. Mined XAI is a small company and the atmosphere was profoundly friendly, encouraging, and optimistic–a great way to start a challenging internship. We–two other interns and myself–spent most of the summer working on an explainable AI platform for diagnosing heart conditions using EKG data.
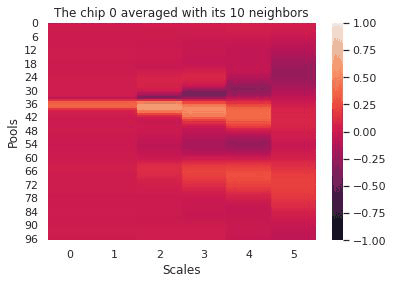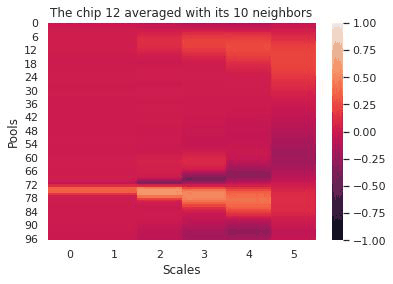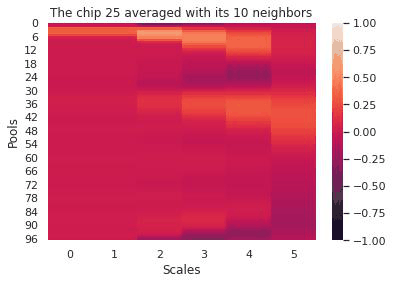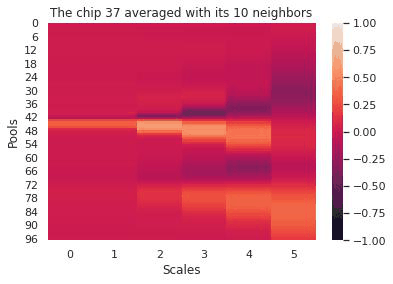
The first few days at Mined XAI focused on meeting the team, understanding the company philosophy (explainability first), and familiarizing myself with Mined XAI’s proprietary algorithms. Mined XAI is a small company and the atmosphere was profoundly friendly, encouraging, and optimistic–a great way to start a challenging internship. We–two other interns and myself–spent most of the summer working on an explainable AI platform for diagnosing heart conditions using EKG data.
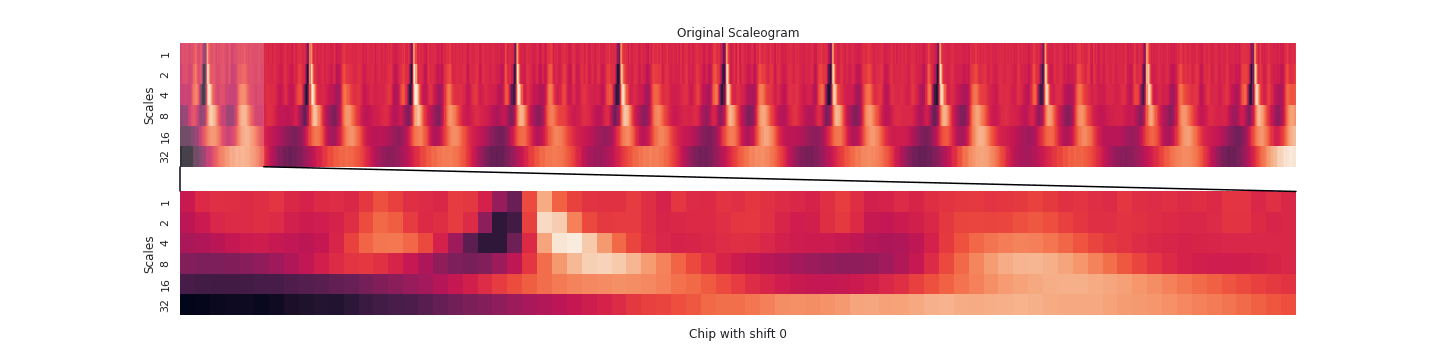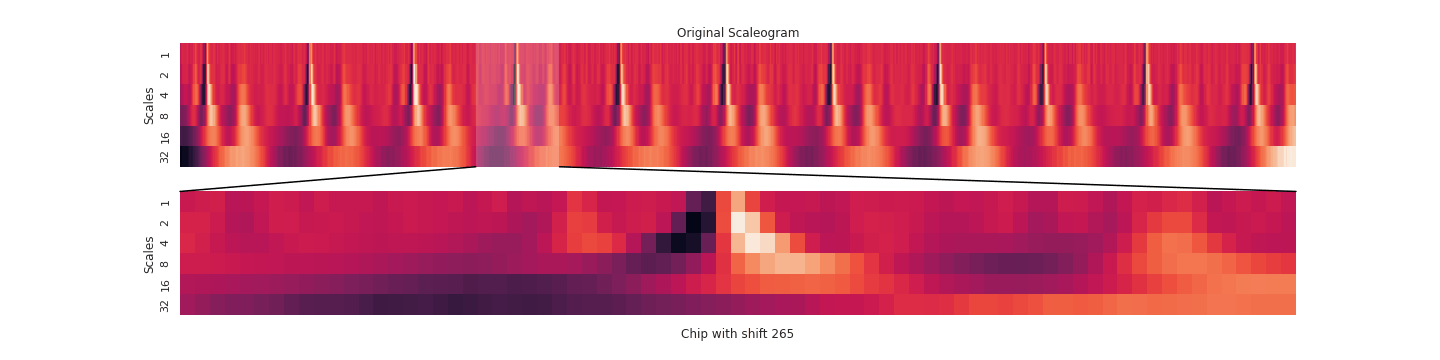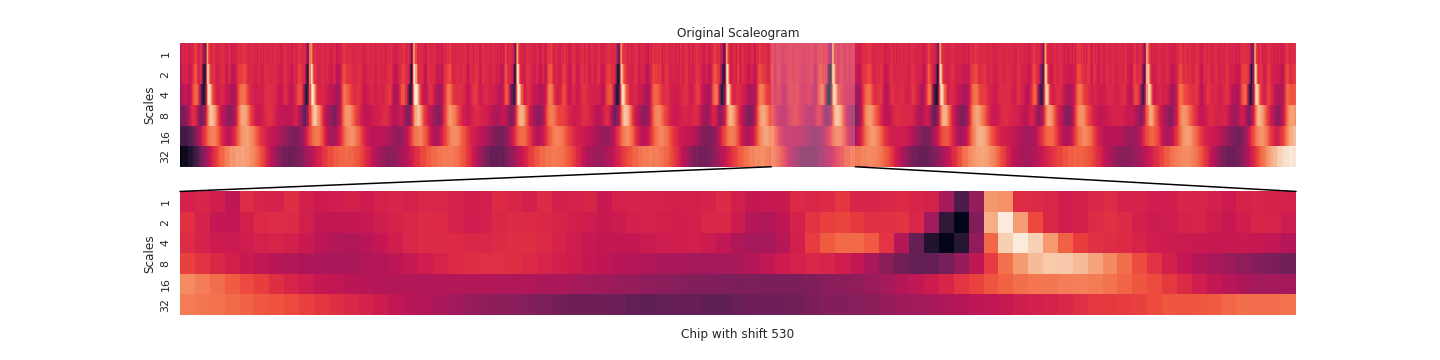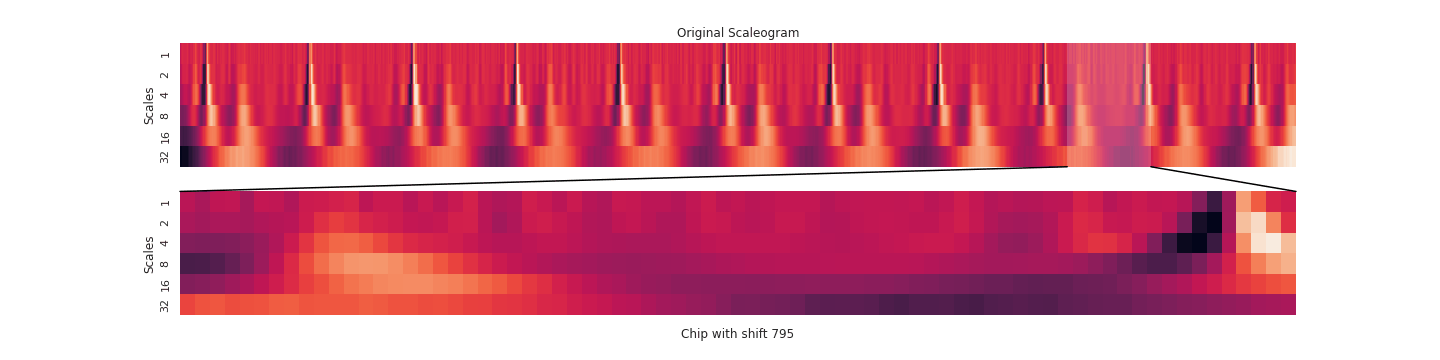
Our pipeline began with signals from twelve different EKG leads. We transformed this data in various ways (using a wavelet transform, by chipping and pooling) and at each step justified the use of the transformation and our choice of hyperparameters by topological data analysis methods. In the end, our transformations yielded a clustering of these EKG “chips” by disease. Because the clustering was imperfect, we designed an evaluation scheme (using logistic regression, K-nearest neighbors, and a smoothing criterion) to make a prediction on whether a given EKG indicated a sickness. To emphasize explainability, our predictions were accompanied by a diagram of the EKG itself and a highlight to indicate the problematic region of the EKG that led to the prediction. That way, a tired cardiologist might save themselves some time when trying to make a diagnosis.
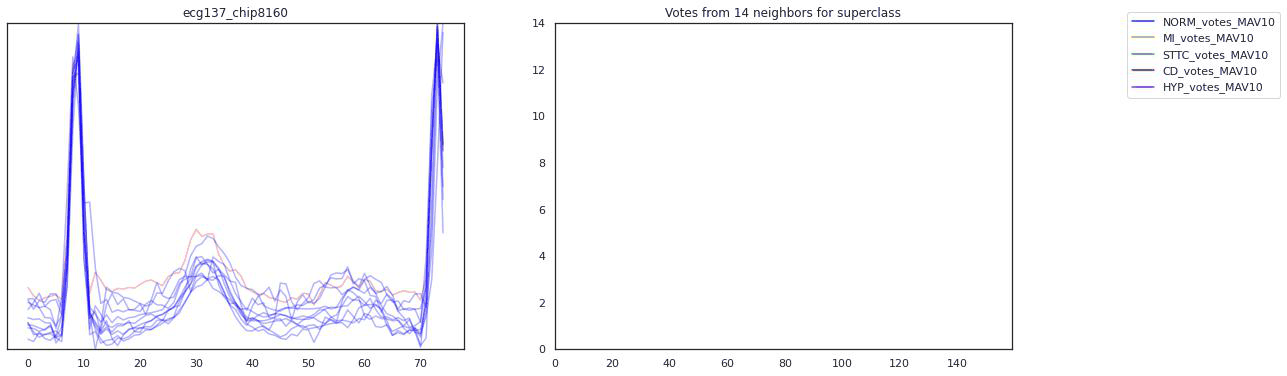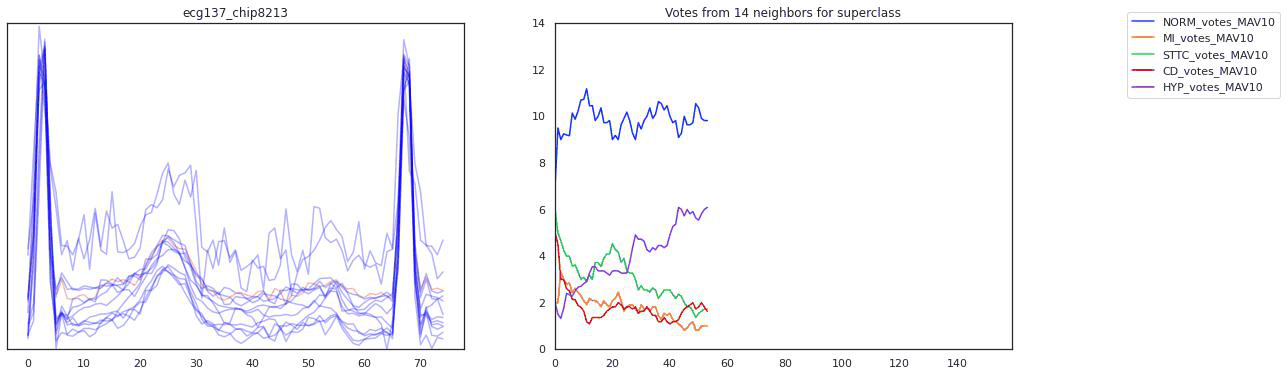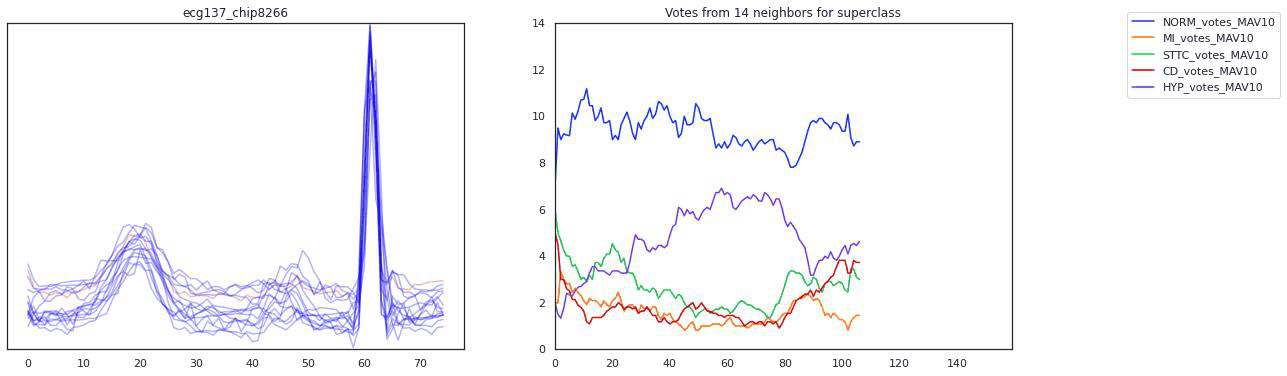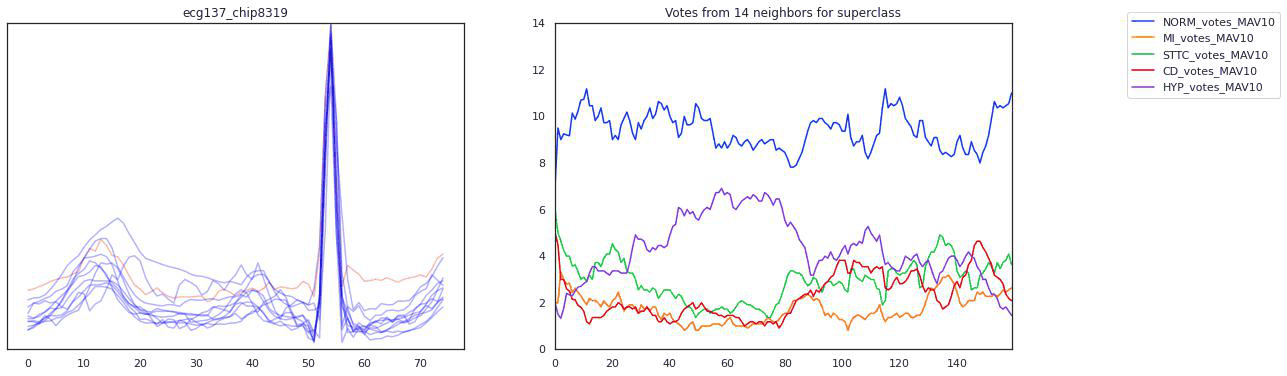
For the Michigan PhDs reading this–a lot of these fancy words I didn’t know at the start of the summer. Trust that if you can pick up math concepts quickly, you will pick up data science concepts quickly too.
A Final Note
As you probably noticed, this story is not strictly linear. There were many adjustments and learning-by-failing experiences. If you are a mathematician at Michigan, you experience that all the time doing research and so neither of those things will deter you from a change in career path. My recommendation is to try out the new, unknown career path. Like me, you might enjoy it more than you thought and find a new passion.